金(ゴールド)データに「異常」発覚!EA検証を揺るがす真実
金データ異常: 日中レンジ>5%の日数が2026年(4ヶ月)で12日。価格も14ヶ月でほぼ倍。
本記事は「金(ゴールド)データに「異常」発覚!EA検証を揺るがす真実」の検証を、はじめての方にも分かるようにまとめたものです。
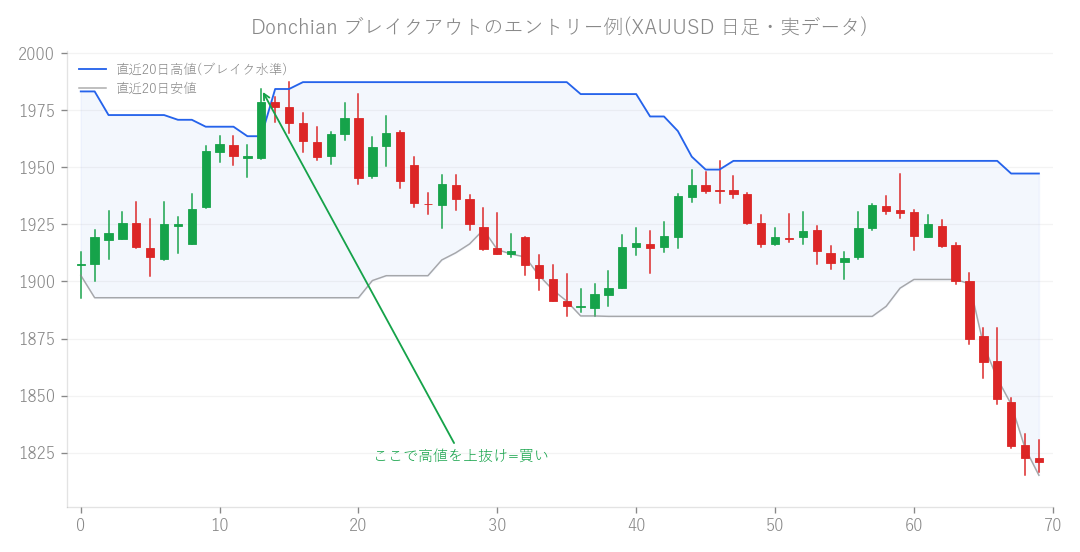
図: ブレイクアウトのエントリー例(XAUUSD 日足・実データ)。直近の高値を上抜けたところで買います。
FXの自動売買(EA)検証をしている中で、金(ゴールド)の過去データにちょっと見過ごせない「異常」が見つかったんです。これは、EAの検証結果を大きく左右する可能性のある、かなり重要な問題なんですよ。
金(ゴールド)のデータに異変が…?
まず最初に気づいたのは、金(ゴールド)のデータです。特に2025年から2026年の4ヶ月間を見てみると、日中の値動き(レンジ)が5%を超える日がなんと12日もあったんです。これ、どれくらい異常かというと、あのコロナショックで世界中がパニックになった2020年でさえ、1年間で10日くらいだったことを考えると、たった4ヶ月でこの回数は尋常じゃないですよね。 さらに、この期間の金価格自体も、たった14ヶ月でほぼ倍になっているという、ものすごい急騰を見せていました。中には日中の値動きが14%にもなる日もあったりして…。「これはさすがに現実的な動きじゃないぞ?」と、データの破損を疑うレベルだったんです。
過去のEA検証結果にも影響が…?ドンチャンチャネルで再検証
この異常なデータを見つけたことで、私たちは一つの大きな懸念を抱きました。それは、「もしかして、これまで検証してきたEAの結果も、この異常なデータの影響を受けているんじゃないか?」ということです。 そこで、以前検証して良い結果が出ていた「Donchian Channel(ドンチャンチャネル)」という有名なトレンドフォロー型EAのアイデアを、改めて健全な期間(2015年〜2024年)のデータでバックテスト(過去のデータを使ってEAの性能を検証すること)し直してみることにしました。もちろん、この期間には先ほどの異常なデータは含まれていません。 結果はどうだったかというと、10年間でプラス3〜11%(年利にすると0.3〜1%くらい)と、かなり控えめな成績に。PF(プロフィットファクター=総利益÷総損失。1を超えると黒字)もほぼ1で、ほとんど利益が出ていない状態でした。 これまでの検証では「+30〜46%でPFが2〜3!」なんて良い数字が出ていたのは、どうやらこの「おかしい2026年の金データ」での急騰にうまく乗っかった結果だったようなんです。つまり、実際の相場ではほとんど機能しない、かなり微弱なものだったということですね。 これは本当に重大な発見で、これまで私たちが検証してきたすべてのバックテスト結果(特に、たくさんのEAの中から勝ち残ったものを見つける『スキャン』テストも含めて)が、この『異常なデータ』によって間違った評価をされていた可能性があるんです。せっかく良いEAを見つけたと思っても、実はデータがおかしかっただけ…なんてことになったら、元も子もないですよね。
データ品質の重要性を痛感!急遽対策を実施
今回の件で痛感したのは、「過学習(過去のデータにEAが最適化されすぎて、未来の相場では通用しなくなること)」だけでなく、「データの品質」もまた、私たちを惑わす「偽の優位性(エッジ)(本当は存在しない優位性)」を生み出す原因になる、ということ。EAの検証って、どれだけ良いEAを見つけられるか、どれだけ厳密にテストできるかが重要だと思われがちですが、その大前提として「使っているデータが健全であること」が本当に大切なんだと改めて学びました。
今後の検証は、よりクリーンなデータで!
そこで、私たちは急遽「データクリーニング層」という、データの異常を自動で検出して取り除く仕組みを作ることにしました。具体的には、日中の値動きが異常に大きすぎるもの、急激な価格の飛び(価格ジャンプ)、出来高がずっとゼロのまま…といった、ありえないデータを見つけて、それらを除外したり修正したりするんです。 そして、この問題にはもう対応済みです!私たちのバックテストエンジンに、異常なデータを見つける機能を組み込み、常にクリーンなデータを読み込むように設定しました。さらに、定期的にデータの点検も行っています。 ちなみに、異常なデータは全体の0.1%程度で、その多くは2020年のコロナショック時の本当にあった激しい値動きだったりするんですが…今回の金(ゴールド)の2025〜2026年のデータは、「単発の異常」というよりも、「ゆっくりと、でも異常なペースで価格が倍増していく」という、ちょっと特殊なケースだったんです。なので、単純な異常検出だけでは見つけにくかった、という背景もあります。 これによって、今後のすべての検証は、この「キレイになったデータ」を前提として行うことになります。皆さんに提供する情報の信頼性を高めるためにも、これは必須の対応だったと考えています。
関連コード(再現用)
この検証は以下のスクリプトで再現できます(リポジトリ参照)。
btengine/dataquality.pyscripts/scan_quality.py