Gold Data Alert: Critical Anomalies Found, Threatening EA Validation!
## The Gold Rush That Wasn't: Unmasking a Sneaky Data Quality Problem
A beginner-friendly summary of the verification: “Gold Data Alert: Critical Anomalies Found, Threatening EA Validation!”.
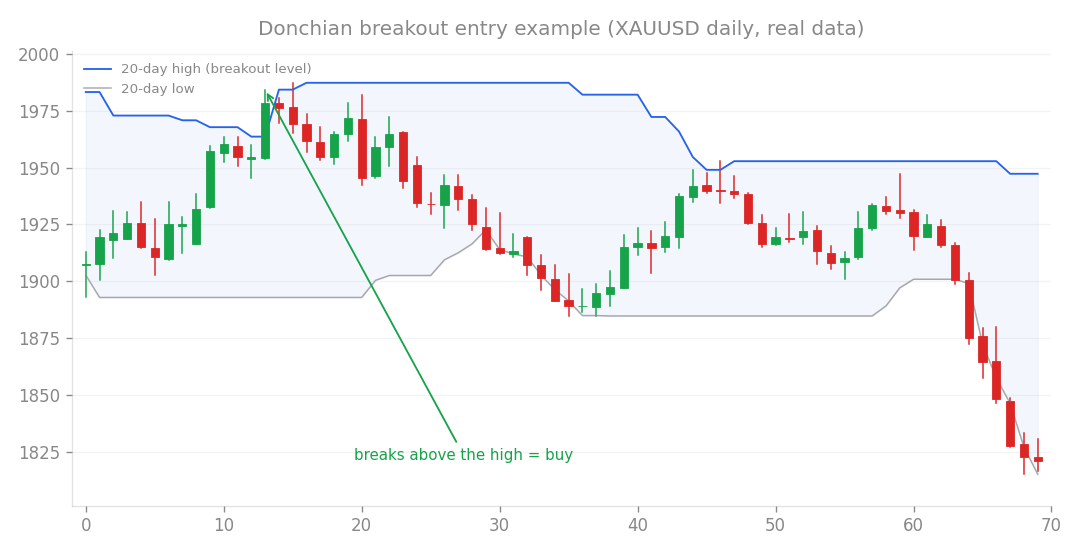
Breakout entry example (XAUUSD daily, real data): buy when price breaks above the recent high.
The Gold Rush That Wasn’t: Unmasking a Sneaky Data Quality Problem
You know how crucial good data is when you’re backtesting EAs (Expert Advisors) for FX trading. We spend so much time worrying about overfitting – making sure our strategies aren’t just “lucky” on past data. But what if the data itself is lying to us? That’s the messy, fascinating problem I recently stumbled upon, and it completely changed how I approach all my testing.
My Golden Headache: A Suspicious Spike
It all started when I was looking at Gold (XAUUSD) data, specifically for the period between 2025 and 2026. Something felt off.
- Unusual Volatility: In just four months of 2026, I saw 12 days where Gold’s intra-day range (the difference between its high and low for the day) exceeded 5%. To put that in perspective, during the entire year of 2020 – remember the COVID-19 chaos? – there were only 10 such days. Twelve days in four months versus ten days in a full, exceptionally volatile year? That’s a huge red flag! I even saw intra-day ranges as high as 14%, which is frankly unrealistic for Gold under normal market conditions.
- Price Surge: On top of that, Gold’s price had almost doubled in just 14 months during this period. While Gold can certainly trend, such a rapid, sustained, and extreme movement raised a lot of eyebrows. My gut feeling screamed: this 2025-2026 Gold data is likely corrupted. It wasn’t reflecting real market conditions.
The Gold Rush That Turned to Fool’s Gold
Before I started digging into the data quality, I had actually run a backtest on a Gold Donchian strategy. If you’re not familiar, a Donchian Channel strategy is a classic trend-following approach that trades breakouts above highs or below lows. My initial test, which included this problematic 2026 data, showed some incredibly promising results:
- Original Results: Profits of +30% to +46% over the test period, with a fantastic Profit Factor (PF) of 2-3.
- Quick jargon explainer: Profit Factor (PF) is calculated as gross profit divided by gross loss. A PF greater than 1 means your strategy is profitable, and 2-3 is generally considered excellent! These numbers looked amazing! Anyone would be excited by that kind of performance. But armed with my new suspicion about the data, I re-ran the exact same Donchian strategy, but this time only on a “cleaner” period: 2015-2024. I wanted to see how it performed without the influence of that questionable 2025-2026 surge. The results were… sobering:
- Clean Data Results: Over a full 10 years, the strategy only yielded a modest +3% to +11% profit (which works out to about 0.3% to 1% annually). The PF was barely above 1, meaning it was just barely profitable. And for some specific parameter settings (like
n=20), it actually showed a net loss. In other words, what looked like a gold mine was just fool’s gold. The impressive 30-46% profit and high PF were almost entirely a product of riding that artificial, likely corrupted price surge in the 2026 data. On genuine, clean data, the strategy’s edge was incredibly weak.
A Bigger Problem Than I Thought
This discovery was a huge “aha!” moment, quickly followed by an “oh no!” moment. If this one strategy’s performance was so heavily skewed by bad data, what about all my other backtests? This is a critical realization: Every single backtest result I’d ever generated, including those from robust “survivor scans” (where we try to find strategies that perform well across many different market conditions or parameters), could be contaminated by this kind of poor data quality. It’s like finding out your kitchen scale has been broken for years, and every recipe you’ve ever followed based on its measurements has been slightly (or completely!) off. We often talk about overfitting – where an EA looks great on historical data but fails in live trading because it’s too tailored to specific past events. But this experience taught me that data quality is an equally potent source of false edges – a perceived advantage that simply isn’t real. The reliability of any trading system verification absolutely hinges on the health and integrity of the underlying data.
My Data Detective Toolkit: Building a Cleaning Layer
This problem was too big to ignore. It became clear that before I could trust any future backtest, I needed to implement a robust solution. So, my immediate and mandatory task was to build a dedicated data cleaning layer. This cleaning layer’s job is to act like a strict quality control inspector for our data. It’s designed to automatically detect and either exclude or correct “abnormal bars” in the price feed. What constitutes an abnormal bar? Things like:
- Outlier Intra-Day Ranges: Days where the price moves an unrealistically large amount.
- Sudden Price Jumps: Unexplained, massive gaps or spikes in price.
- Consecutive Zero Volume: Periods where there’s no trading activity for an extended time, which can indicate missing data.
This data cleaning layer is now a fundamental prerequisite for all our future verifications. It’s integrated into our system (
btengine/dataquality.py) and is now the default when loading data (loader.load(clean=True)). We also have scripts (scripts/scan_quality.py) to regularly check for anomalies.
The Plot Thickens (And What I Learned)
After implementing the initial data quality checks, I found that “truly abnormal” bars (the kind that our new detector catches) make up only about 0.1% of our total data. Many of these are actually real, albeit extreme, events like those seen during the 2020 COVID-19 market turmoil. So, the system is working well to catch those sudden, isolated spikes. However, here’s the kicker, and it highlights the ongoing challenge: the Gold 2025-2026 issue wasn’t caught by this initial single-bar anomaly detection. Why? Because it wasn’t a series of isolated, sudden spikes or gaps. Instead, it was a more insidious “smooth doubling” of price over an extended period. Our system was designed to catch sharp, individual “bad” data points, but this problem was a trend of highly improbable data. It was like a slow, steady poisoning rather than a sudden shock. This experience has been a powerful lesson:
- Data quality is paramount. It’s not just about avoiding overfitting your strategy; it’s about making sure the data you’re fitting to is even real.
- “Garbage in, garbage out” is incredibly true. The reliability of any verification, any backtest, and any perceived edge is completely dependent on the health and integrity of your data.
- Data cleaning is an ongoing challenge. Some data issues are obvious, like a single, huge spike. Others, like a smoothly trending, yet fundamentally incorrect, price movement, are much harder to spot and require more sophisticated detection methods. We’ve taken a huge step forward by implementing our data cleaning layer, and it’s now the foundation for all our future testing. But as with any deep dive into data, there’s always more to learn and more subtle issues to uncover. The quest for truly reliable EA verification continues!
Code to reproduce
You can reproduce this with the following scripts (see repo).
btengine/dataquality.pyscripts/scan_quality.py